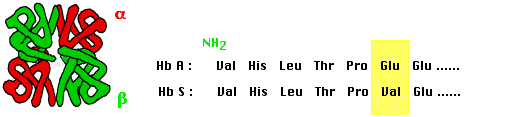
1 - NOTION DE CODE GENETIQUE
L'hypothèse "un gène une protéine" évoquée au
chapitre III a été confortée bien avant le développement des technologies de
l'ADN recombinant.
Ingram, vers 1957 a été l'un des premiers à établir la
relation précise entre une mutation bien caractérisée ayant comme manifestation
phénotypique une maladie héréditaire grave : l'anémie falciforme (ainsi nommée
en raison de la forme des hématies des sujets homozygotes pour la tare) et une
protéine spécifique : l'hémoglobine. L'hémoglobine normale est de type A et
composée de quatre motifs polypeptidiques : deux chaines alpha et deux chaines
beta, l'hémoglobine S, des sujets atteints est également composée des quatre
sous unités mais elle se distingue de la A par sa mobilité
électrophorétique.
Par des méthodes d'analyse d'oligopeptides et de
séquençage protéique que nous ne détaillerons pas, il fut montré que
l'hémoglobine S diffère de la normale (A) par un seul acide aminé dans les
chaines ß :
Le remplacement d'un acide aminé diacide (acide glutamique) par un neutre explique la différence de mobilité à l'éléctrophorèse. Par ailleurs, tous les autres acides aminés sont identiques, autrement dit, l'unité d'effet d'une mutation peut être le changement d'un seul acide aminé dans une protéine.
* Remarque : La biologie moléculaire des protéines a permis de comprendre qu'une très légère altération de la structure primaire pouvait bouleverser les structures secondaires et tertiaires avec des conséquences physiologiques considérables. Ce n'est pas toujours le cas, tout dépend de la position de la modification dans la protéine, certaines substitutions d'acides aminés ne peuvent avoir que peu ou pas d'effet.
Quelques années plus tard, Yanofsky établit une relation entre la structure du gène et la structure primaire de la
protéine.
Par les techniques de cartographie à haute résolution
adaptées aux bactéries, il positionne plusieurs mutations supposées ponctuelles
dans un cistron codant pour une sous unité A de la tryptophane synthétase d'E.
coli. Il parvient également à séquencer le produit de ce cistron (la protéine)
pour le gène sauvage et les variants. L'étude de la séquence en acides aminés de
la tryptophane synthétase A des mutants confirme les conclusions précédentes :
le plus souvent, un seul acide aminé est modifié, cependant, dans certains cas,
les protéines sont tronquées, l'extrémité COOH est prématurée.Yanofsky peut donc
construire une carte des effets des mutations dans la séquence protéique et la
confronter à la carte génétique des mutations.
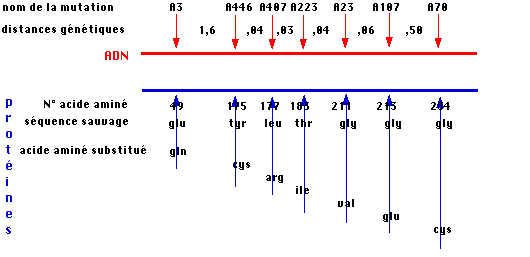
La figure ci-dessus montre une extraordinaire colinéarité entre les deux. Ceci suppose que la structure primaire de toute protéine soit spécifiée par un "gène", soit une séquence d'ADN.
* Remarque : extraordinaire ne veut pas dire parfaite quant aux distances, il faut bien comprendre la différence technique de réalisation des deux cartes : pour les protéines, il s'agit de cartes physiques, positionnant les acides aminés les uns après les autres, pour le cistron, il s'agit de carte génétique reposant sur des phénomènes de recombinaison in vivo .
Ces découvertes montrent clairement que l'information est codée. Chaque "gène" code une protéine particulière.
La découverte de l'ADN en tant que support de l'information laisse supposer que la séquence des nucléotides n'a pas de rôle dans la structure de la molécule mais constitue le code de la séquence des acides aminés dans les protéines.
Il existe donc un transfert d'information. Le code
génétique représente le système de correspondance entre la séquence des
nucléotides dans les acides nucléiques et celle des acides aminés dans les
protéines.
La correspondance n'est pas un nucléotide pour un acide aminé
puisqu'il n'existe que 4 nucleotides différents pour 20 acides aminés
différents. Le code génétique repose sur une combinaison de nucléotides. Une
combinaison de 2 parmi 4 possibles ne peut suffire, une combinaison de 3 (64
possibilités) est vraisemblable et le système de triplets (3 nucléotides pour spécifier un acide aminé) est
effectivement celui qui est universellement utilisé.
Bien avant que l'on ait réussi à déchiffrer l'intégralité du code, l'étude de
certaines mutations a apporté des preuves génétiques à la colinéarité entre la
séquence des triplets dans un cistron et celle des acides aminés dans la
protéine qu'il spécifie.
Le mécanisme de traduction implique la lecture des triplets les uns après
les autres si l'on suppose le code non chevauchant (le fait que des mutations
n'entrainent la modification que d'un seul acide aminé dans une protéine le
laisse supposer). Cette traduction implique une notion très importante, celle de
cadre de lecture : dans toute séquence d'ADN, si l'on
admet le système de triplets, il existe 3 cadres de lecture potentiels.
Par exemple, la séquence :
... A C G A C G A C G A C G A C G A C G A C G A C G A C G A ...
peut etre décomposée en
ACG ACG ACG ACG ACG etc
soit, comme on le verra plus tard, une série de mots de code pour l'acide aminé thréonine.
*Remarque : jamais on ne trouve de telles séquences monotones dans l'ADN, il s'agit d'aider à la compréhension.
ou en CGA CGA CGA CGA CGA etc soit arginine
ou en GAC GAC GAC GAC GAC etc soit acide aspartique
Bien entendu, pour un cistron donné,une seule possibilité peut conduire à une
protéine normale, la traduction assurera une lecture
correcte.
Des mutations par insertion ou délétion d'un seul nucléotide dans
une séquence sauvage (correspondant à l'allèle habituel) ont permis de montrer
l'importance du cadre de lecture.
Soit une séquence sauvage hypothétique (et peu vraisemblable) :
1 2 3 4 5 6 etc
5' GCT GCT GCT GCT GCT GCT GCT GCT GCT 3'
pour le brin codant, selon les conventions, le produit de transcription du brin complémentaire de celui-ci est
5' GCU GCU GCU GCU GCU GCU GCU GCU GCU 3'
et la protéine :
NH2 Ala Ala Ala Ala Ala Ala Ala Ala Ala COOH
Supposons une mutation par insertion d'une adénosine en position 7 , les répercussions sont les suivantes:
*
ADN : GCT GCT AGC TGC TGC TGC TGC TGC TGC
ARN : GCU GCU AGC UGC UGC UGC UGC UGC UGC
Protéine : Ala Ala Ser Cys Cys Cys Cys Cys Cys
à partir de l'insertion, toute la protéine est fausse, et certainement non fonctionelle
De même, une mutation par déletion d'une Guanine en 16 a également un effet de décalage du cadre de lecture :
*
ADN : GCT GCT GCT GCT GCT
CTG CTG CTG CTG
ARN : GCU GCU GCU GCU GCU CUG CUG CUG CUG
Protéine : Ala Ala Ala Ala Ala Leu Leu Leu Leu
Par contre, si l'on examine un double mutant, on s'aperçoit que la 2ème mutation rétablit le cadre de lecture, elle supprime l'effet de la première.
*
ADN : GCT GCT AGC TGC TGC TCT GCT GCT GCT
ARN : GCU GCU AGC UGC UGC U CU GCU GCU GCU
Protèine : Ala Ala Ser Cys Cys Ser Ala Ala Ala
* Remarque : Cette suppression de l'effet d'une mutation par une autre est une notion importante. Elle est est, ici, intra génique la deuxième mutation a lieu dans le même cistron que la première. Ce n'est pas toujours le cas, le phénomène de suppression peut être inter génique, physiologique ...
Trois mutations successives auraient des effets différents selon leur signe
(par convention : + = insertion, - = délétion)
Trois mutations de même signe
rétablissent le cadre de lecture et le résultat est l'insertion ou la délétion
d'un seul acide aminé dans la protéine.
Un acide aminé est donc bien spécifié par un système à trois nucléotides.
Par la suite, grâce à des expériences reposant sur des systèmes de synthèse
protéique in vitro, la signification des 64
combinaisons possibles de trois nucléotides (parmi un choix de quatre) a 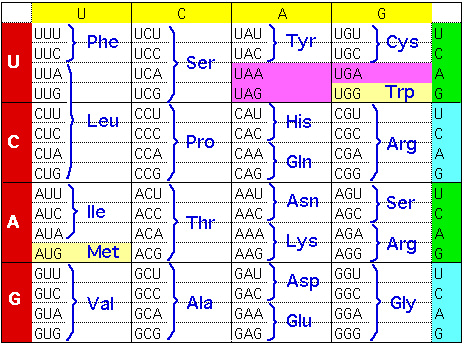 pu être
élucidée. Les résultats sont compilés dans le tableau ci-contre. Trois seulement
n'ont pas de sens en termes d'acides aminés et des arguments génétiques
montreront qu'il s'agit de signaux d'arrèt de la traduction. 61 triplets ont une
signification pour l'un des 2O acides aminés et seront appelés des codons. Le tableau met en évidence de nombreux synonymes (on dit que le code est "dégénéré"). Seuls la
méthionine et le tryptophane ne sont codés que par un seul triplet, les autres
le sont par des familles de 2, 3, 4 et même 6 (arginine). A part cette exception
(l'arginine), il est important de remarquer que les deux premiers nucléotides de
triplets codant pour un acide aminé donné sont les mêmes, seul le troisième est
variable.
pu être
élucidée. Les résultats sont compilés dans le tableau ci-contre. Trois seulement
n'ont pas de sens en termes d'acides aminés et des arguments génétiques
montreront qu'il s'agit de signaux d'arrèt de la traduction. 61 triplets ont une
signification pour l'un des 2O acides aminés et seront appelés des codons. Le tableau met en évidence de nombreux synonymes (on dit que le code est "dégénéré"). Seuls la
méthionine et le tryptophane ne sont codés que par un seul triplet, les autres
le sont par des familles de 2, 3, 4 et même 6 (arginine). A part cette exception
(l'arginine), il est important de remarquer que les deux premiers nucléotides de
triplets codant pour un acide aminé donné sont les mêmes, seul le troisième est
variable.
Etant donné que l'ADN ne sert pas physiquement de support à la synthèse des protéines, il existe un flux d'information génétique dans la cellule.
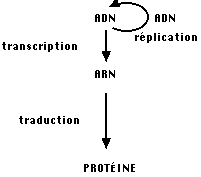 *Remarque : Un premier flux d'information a déjà été étudié" avec la
réplication de l'ADN, il représente l'état "reproduction" de la cellule, celui
qui va être abordé représente l'aspect "métabolisme".
*Remarque : Un premier flux d'information a déjà été étudié" avec la
réplication de l'ADN, il représente l'état "reproduction" de la cellule, celui
qui va être abordé représente l'aspect "métabolisme".
Ce flux d'information se fait en réalité en deux étapes : il existe un
intermédiaire entre la séquence d'ADN - unité d'information et la protéine
spécifiée : l'ARN messager. Par transcription, la
séquence d'ADN est reproduite dans une séquence d'ARN qui repose, elle aussi sur
un système à 4 nucléotides.
La seconde étape est la traduction c'est à dire la réalisation d'une protéine
spécifiée par l'ARN messager avec passage d'un alphabet à 4 lettres à un
alphabet à 20 lettres.
| relire ? | sommaire cours | sommaire GENET |