|
Analyse
bioinformatique des séquences
Les programmes de comparaison de séquences ont pour but de repérer les endroits où se trouvent des régions identiques ou très proches entre deux séquences et d'en déduire celles qui sont significatives et qui correspondent à un sens biologique de celles qui sont observées par hasard. 
et la ressemblance non parfaite que l'on qualifie de similitude.
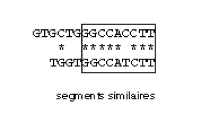
Il existe bien évidemment plusieurs niveaux de similitude et les programmes s'attachent à repérer les régions où l'on trouve généralement des éléments identiques ou très similaires suffisamment nombreux pour que la ressemblance soit intéressante. En fait on considérera que la ressemblance est significative lorsque son score est supérieur ou égal à un score seuil que l'on s'est fixé (cf. l'évaluation des résultats). Bien entendu, pour l'identité, seules les matrices unitaires sont autorisées comme matrices de scores élémentaires alors que pour les autres ressemblances, toutes les matrices peuvent être employées. La notion d'alignement, elle, suppose la recherche des positions auxquelles il est possible de faire des insertions ou des délétions afin d'optimiser le score d'une comparaison. 
On considère qu'un programme est un programme d'alignement s'il possède au moins cette étape. La plupart des programmes de comparaisons de séquences s'appuient sur une de ces trois notions (la recherche de segments identiques, de segments similaires ou d'alignements) pour faire ressortir des ressemblances entre séquences. Nous verrons que certains programmes, essentiellement pour les comparaisons avec les bases de données, peuvent utiliser une combinaison de ces principes fondamentaux. Il existe évidemment plusieurs méthodes pour mettre en œuvre ces principes, nous décrirons ici celles qui les illustrent le mieux et qui sont souvent les plus utilisées. |
