Tests sur les classifications
Dans cette partie, nous vous présentons deux méthodes, l'une permettant de tester la signification statistique d'une classification, l'autre pour tester la robustesse d'une classification.
1- Signification statistique d'une classification
La question que l'on se pose souvent est de savoir lorsque l'on introduit une classification dans des données, si cette classification a un sens. En d'autres termes, les classes qui sont formées permettent-elles d'expliquer un maximum de la variabilité inscrite dans les données?
Le principe proposé est le suivant:
Lorsque l'on introduit des classes dans les données, il faut constater une diminution de la variabilité résiduelle, ce qui veut dire qu'en créant les classes on a expliqué une grande partie de la variabilté. On peut traduire cela en écrivant:
SCsans-classes-SCclasses = SCrésiduel qui tend vers 0
Si SCrésiduel tend vers 0 alors Fclasse= SCclasse/SCrésiduel tend vers l'infini.
Si Fclasse est grand (tend vers l'infini), on a une amélioration du signal/bruit ce qui veut dire que la classification introduite est statistiquement significative et par conséquent son introduction est justifiée.
Ce pincipe proposé ci-dessus permet d'avoir une base statistique pour tester si une classification est justifiée.
2- Robustesse d'une classification
La question qui se pose ici est de savoir comment tester si une classification que l'on a introduite dans un environnement va être robuste (valable) dans un autre environnement. En d'autres termes, la classification que l'on introduit est-elle généralisable ?
Cette discussion va être présentée au travers d'un exemple mené par le Pr DARBON et son équipe à l'hopital de Montpellier sur des patientes atteints de cancer du sein (Publication). Le contexte est le suivant:
On dispose des données PCR de 199 patientes atteints d'un cancer du sein et ce pour 47 gènes à chaque patiente. On cherche une combinaison de gènes qui seraient spécifiques d'une nouvelle catégorie de cancer du sein (signature PCR), c'est à dire à établir des sous-types de la maladie. Dans ce genre de problématique, on peut toujours trouver un résultat. La question qui se pose alors est de savoir si la classification établie est robuste, c'est à dire va-t-elle discriminer aussi les données dans un autre contexte (données provenant d'un autre hopital par exemple).
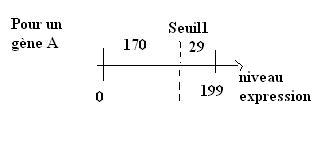
Une méthode pour tester si une classification est robuste (généralisable) est d'opposer chaque classe aux autres et pour une classe donnée trouver le seuil qui maximise l'écart entre la classe étudiée et les autres. Ce seuil sera défini non pas en valeur absolue, mais en proportion ce qui permet de travailler sur des rangs et pas des valeurs.
On passe donc de données continues à des données discrètes: pour chaque gène et pour une classe donnée, on regarde par un test de chi2 quel est seuil qui maximise le le nombre de patientes dans cette classe.
On obtient ainsi une signature moléculaire de chaque classe: pool de gènes pour lesquels le niveau d'expression dépasse le seuil qui leur a été associé par l'analyse de chi2.

© Université
de TOURS - GÉNET
Document modifié le
25 mars, 2010
![]()
![]()
![]()