3 TRADUCTION
C'est le mécanisme par lequel le flux d'information va passer de la forme acide nucléique (alphabet à 4 lettres) à la forme protéine (alphabet à 20 lettres) selon un code universel.
*Remarque : peu de temps après avoir réussi à déchiffrer le code génétique (c'est à dire après avoir attribué une signification à chaque triplet de bases) et montré que le même code est utilisé par les virus, les procaryotes et les eucaryotes, il devint clair que certains organites des cellules eucaryotiques (mitochondries et chloroplastes) possèdent leur propre information génétique. Le flux d'information dans ces organites reste tout à fait classique mais le transfert mitochondrial d'acide nucléique à protéines utilise un code différent du code universel. La façon dont ont évolué les codes génétiques mitochondriaux (ils diffèrent en effet selon les éspèces) reste une énigme.
Sur le plan génétique, les éléments essentiels de la traduction sont :
* Remarque : Sur le plan biochimique, d'autres
enzymes et cofacteurs interviennent pour assurer la formation des liaisons
covalentes (liaison peptidique en particulier) et toute la cinétique de la
traduction, ils ne seront pas évoqués ici.
3.1 LES ARN DE TRANSFERT ET LA LIAISON DES ACIDES AMINES
Il n'existe aucune affinité entre les ARN messagers et les acides aminés, ni in vivo ni in vitro, la jonction entre le code et ce qu'il spécifie se fait par l'intermédiaire de molécules adaptatrices : les ARN de transfert. Ces petites molécules (environ 70 nucléotides) possèdent deux fonctions essentielles : la possibilité, pour chacune d'entre elles de se lier à un acide aminé spécifique et d'autre part de reconnaitre un codon précis grâce à un anticodon c'est à dire un triplet complémentaire du codon. La reconnaissance anticodon - codon repose sur la complémentarité des bases et met en jeu la structure primaire des ARN de transfert, la reconnaissance spécifique d'un acide aminé est beaucoup plus complexe et implique l'architecture, en trois dimensions, de ces molécules particulières.
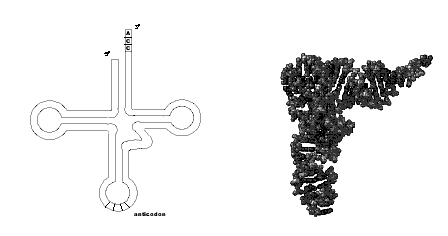
Les ARN de transfert
L'image d'une structure secondaire en "feuille de trèfle" représentée dans la figure ci-dessous est familière et fait ressortir la présence de palindromes et la structure secondaire qui en découle.
Classiquement on va distinguer plusieurs régions caractéristiques:
Cette représentation plane ne donne pas une idée précise de la structure
tertiaire, grossièrement en forme de "L", maintenue par des liaisons hydrogène.
Or, c'est certainement cette structure qui conditionne la fonction de ces
molécules adaptatrices.
*Remarque : les ARN de
transfert contiennent des bases dites "rares" telles que pseudouridine,
dihydrouridine, inosine ... qui sont en fait des bases
modifiées après la transcription. Ces bases contribuent largement à
l'établissement de la structure tridimensionnelle par des liaisons hydrogène
inhabituelles.
Les aminoacyl-ARNt synthétases
Les enzymes capables de catalyser la "charge" des ARN de transfert, c'est à dire de relier le bon acide aminé à l'ARNt porteur du bon anticodon sont appelées aminoacyl-ARNt synthétases, il en existe autant que d'acides aminés et chacune est capable de reconnaitre les différents ARNt synonymes.

La figure ci-dessus souligne l'importance des structures tertiaires (malheureusement représentées en plan) dans la spécificité de la charge des ARNt.
* Remarque : Les aspects énergétiques ne sont pas abordés ici.
3.2 LES RIBOSOMES ET L'ENCHAINEMENT DES ACIDES AMINES
Les ribosomes sont des "organites" de composition complexe souvent comparés à
des "têtes de lecture" se déplaçant sur l'ARN messager. Chacun est constitué de
deux sous unités ribonucléoprotéiques géneralement
désignées par leur coefficient de sédimentation en Svedbergs (S), de même que
les molécules d'ARN qui entrent dans leur composition, celle-ci est résumée dans
le tableau suivant pour un ribosome procaryotique de 70 S
|
|
|
(nb de molécules) | |
|
grande sous unité |
50S |
23S |
34 |
* Remarque : Les ribosomes eucaryotiques (cytoplasmiques) sédimentent vers 80 S avec des sous unités 40 S et 60 S, leur composition détaillée varie légèrement selon le règne (animal, végétal, champignons)
Les deux éléments du ribosome sont indispensables à la traduction et vont se mettre en place au moment de la phase d'initiation de ce processus. Dans le cytoplasme, leur association spontanée, en absence de traduction, est empêchée par l'association d'une protéine supplémentaire avec la petite sous unité : le "facteur" d'initiation IF3.
La petite sous unité reconnait l'ARN messager et s'y fixe, la grosse sous unité vient compléter le ribosome et présente des sites de reconnaissance et de traitement de chaque ARN de transfert chargé en acide aminé.
Les schémas présentés dans les figures ci-dessous sont loin de la réalité car encore une fois ils représentent les événements en deux dimensions alors que tout repose sur la structure tridimensionnelle des différents acteurs, tout est une question de "creux et de bosses" disposés à bon escient !
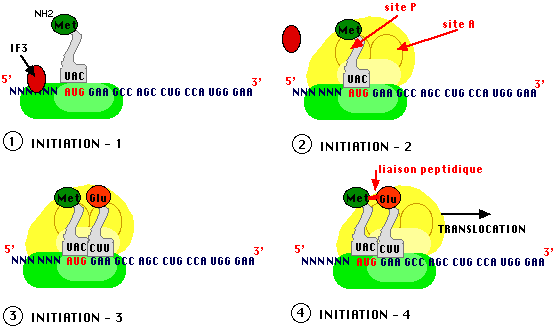
Ainsi, deux sites essentiels de la grosse sous unité (A et P) permettent de recevoir des ARN de transfert avec un espacement correspondant exactement à deux triplets successifs. Le site P (par lequel la Protéine naissante sort du complexe de traduction) ne peut être reconnu que par un ARN de transfert caractéristique de l'initiation (ARNti) systématiquement chargé en méthionine (chez les eucaryotes) ou en formyl-méthionine (chez les procaryotes). Cet ARN chargé est différent de celui qui sera utilisé en cours de synthèse pour apporter une méthionine là où le code le demande bien que le codon spécifiant la méthionine (A U G) soit unique, tout repose sur les structures tertiaires de l'ARNt d'initiation (ARNtimet) et des autres. Des facteurs protéiques d'initiation (IF), formant un complexe avec l'ARNti chargé (en méthionine ou en formyl methionine) jouent un rôle essentiel dans la reconnaissance du site P.
Lorsque cet assemblage est effectué, un second ARNt chargé vient occuper le site A (sur lequel arrivent les Acides Aminés). Le choix repose sur l'appariement codon-anticodon de telle sorte que l'acide aminé spécifié par le deuxième codon est en contact avec la méthionine d'initiation, une liaison peptidique peut s'établir entre les deux acides aminés.
* Remarque : Dès maintenant, il est clair que la fidélité du transfert de l'information fait intervenir l'appariement codon-anticodon, on sait que les deux premiers nucléotides du codon sont reconnus d'une façon très stricte, les règles d'appariement du troisième sont différentes.
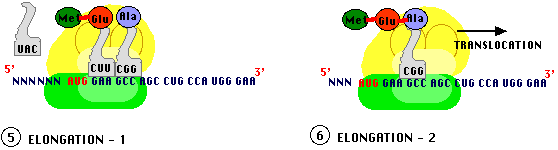
L'élongation va faire intervenir une translocation du ribosome c'est à dire un décalage correspondant exactement à un triplet de nucléotides. Le résultat est que le site A se trouve libre pour recevoir un troisième ARNt chargé d'un troisième acide aminé (spécifié par le codon "en cours" face au site A) ce qui entraîne une deuxième liaison peptidique, les ARNt amont (côté site P) sont libérés. Ici encore, des facteurs protéiques, spécifiques de l'élongation (EF) forment des complexes avec les ARNt chargés pour assurer l'installation dans le site A.Les translocations se poursuivent avec adjonction séquentielle d'acides aminés à la chaine en cours jusqu'à la terminaison.
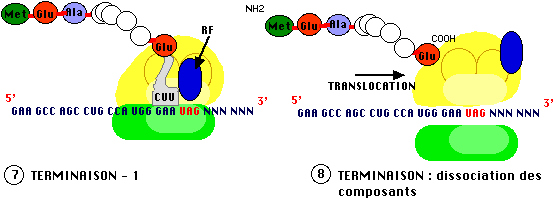
Celle
ci est programmée, dans l'ARN messager par un triplet signifiant l'arrêt (codons
stop : U A G appelé amber, U A A ochre et U G A opal, terminologie liée à
l'historique de la découverte de ces signaux d'arrêt. Aucun ARN de transfert ne
possède d'anticodon correspondant, le site A reste inoccupé, la translocation
s'arrête et la protéine est relachée.
* Remarque : Toute mutation, dans un
cadre de lecture, conduisant à l'apparition d'un de ces triplets est une
mutation "non sens" et conduit à une fin prématurée de la protéine.
| Les cistrons sont transcrits en ARN messagers eux
mêmes traduits, au niveau des ribosomes lors de la synthése de protéines
dont la séquence est spécifiée par la séquence de l'ADN. Ces mécanismes
complexes permettent la réalisation d'un phénotype protéique parfaitement
conforme à l'information codée.
Le code génétique est le système de correspondance entre les acides nucléiques et les protéines, il utilise des triplets de nucléotides non chevauchants. |
| relire ? | sommaire cours | sommaire GENET |