Présentation de la méthode ANOVA ![]()
Pour mieux comprendre ce qu'est une analyse de variance, prenons l'exemple d'un auteur qui veut absolument conserver l'ensemble de ces résultats et les publier et un éditeur dont la principale préoccupation est de gâcher le moins possible de papier.
Prenons l'exemple d'un tableau de chiffres, la méthode ANOVA permet de trancher entre les deux protagonistes précédents, en résolvant le problème de savoir si cela vaut la peine de garder ce tableau de chiffres.
Dans ce contexte, il faut aussi savoir qu'un tableau de chiffre ne peut être publié que si l'on est capable de le commenter. Si l'on considère le tableau de données initiales sur l'orge qui est à 3D, il est clair que l'on ne sait pas le commenter. Une solution est de se limiter à 2D, en décomposant le tableau initial en sous tableaux de dimension inférieure.
Décomposition en sous tableaux
Le tableau de données initiales contient 60 données, avec un écart type de 27,5 qui montre que toutes les cases ne sont pas homogènes ce qui mérite de regarder plus en détails les sous tableaux. Par exemple, on peut construire la tableau lignée x lieu comme ci-dessous:
| Lignée | 1 | 2 | 3 | 4 | 5 | 6 | Total1 |
| Manchuria | 161,7 | 247,0 | 185,4 | 218,7 | 165,3 | 154,6 | 1132,7 |
| Svansota | 187,7 | 257,5 | 182,4 | 183,3 | 138,9 | 143,8 | 1093,6 |
| Velvet | 200,1 | 262,9 | 194,9 | 220,2 | 165,8 | 146,3 | 1190,2 |
| Trebi | 196,9 | 339,2 | 271,2 | 266,3 | 151,2 | 193,6 | 1418,4 |
| Peatland | 182,5 | 253,8 | 219,2 | 200,5 | 184,4 | 190,1 | 1230,5 |
| Total2 | 928,9 | 1360,4 | 1053,1 | 1089,0 | 805,6 | 828,4 |
Le premier commentaire que l'on peut faire sur ce tableau en regardant les sommes des lignes et des colonnes (total1 et total2), c'est que toutes les lignées n'ont pas le même rendement et que selon les lieux les rendements diffèrent aussi.
Le second commentaire concerne la distribution des données. Si elle est homogène, les tableaux 1D suffisent et les seules informations pertinentes à conserver pour l'éditeur, ce sont les deux tableaux Total1 et Total2.
Par contre, si cela est hétérogène, c'est à dire que certaines lignées sont meilleures sur certains lieux, comment quantifier cette information 2D ?
C'est là qu'intervient la méthode ANOVA proposée par Fisher ( Mather K. - Analyse statistique en biologie . ACTA Editions GAUTHIER-VILLARS , PARIS 1965). En effet, Fisher a créé et proposé une mesure objective de cette information 2D, en plus des informations contenues dans les tableaux 1D. Cette mesure permet de quantifier la part d'information contenue dans le tableau 2D, et de répondre ainsi si l'on revient à l'exemple de départ à la question que se pose notre éditeur de savoir si oui ou non il doit publier l'intégralité des résultats que lui présentent l'auteur ou si les tableaux 1D suffisent.
![]()
La méthode ANOVA
Le critère objectif qui nous intéresse est la variance dont la formule est la suivante:

Avec:
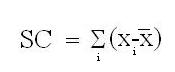
La variance correspond à une mesure de l'information moyenne contenue dans les données (moyenne car on divise la quantité d'information totale (SC) par le nombre de dégrés de liberté).
Il faut retenir aussi que dans un tableau de données:
SC total= SC lignes + SC colonnes + SC résiduel avec SC résiduel qui quantifie l'information spécifique au tableau > 1D. Lorsque l'on recherche la variablité résiduelle, il suffit donc de calculer:
SC résiduel=SCtotal-SCcolonnes-SClignes.
![]()
Les différentes situations
Sortons provisoirement de notre exemple sur l'orge sur lequel nous reviendrons, et intéressons nous aux différents cas qui peuvent se présenter lorsque l'on analyse les sommes des carrés des écarts (SC).
Dans le logiciel Excel, on bénéficie d'une fonction SOMME.CARRES.ECARTS() qui nous permet dans le fichier exemple d'observer les différents cas qui peuvent se présenter:
Notons tout d'abord que chaque case de tableaux contient la somme des carrés divisée par le nombre d'observations qui sont additionnéées.
cas1: SC résiduel = 0 (minimal), toute l'information est contenue dans les tableaux 1D, conserver les tableaux 2D n'apporte rien.
cas2: SCrésiduel = 12 (maximal), toute l'information est en 2D, l'information contenue dans les tableaux 1D est nulle.
cas3: SC résiduel >0, impossible de trancher entre le bruit (variabilité liée au hasard) ou à un véritable effet biologique des facteurs entre eux.
La variabilité résiduelle calculée peut être due soit à un bruit de fond soit à un phénomène biologique (ce phénomène introduisant une intéraction entre les 2 facteurs). Pour trancher entre les 2, la seule solution est de repoduire l'expérience de nombreuses fois afin de vérifier si la variabilité se fait toujours dans le même sens. Si le biais se fait toujours de façon identique, on pourra conclure que ce n'est pas lié au hasard.
On retiendra que chaque fois que l'on veut mettre en évidence une intéraction entre deux facteurs, il faut montrer que c'est reproductible donc refaire l'expérience X fois.
Le cas des données de Mather
Revenons maintenant sur l'analyse des données disponibles sur l'orge. Comme on l' a déjà explicité, le tableau 3D étant inexploitable tel que, on décompose ce tableau en sous tableaux de dimensions inférieurs. Dans le fichier Orge.xls, vous trouvez la description de tous les tableaux 2D et 1D que l'on peut construire à partir des données initiales.
Les différentes informations calculées à partir de ces tableaux 1D et 2D sont présentées ci-dessous:
| ANOVA | Carrés | ddl | Intéraction | ddl | Variance | F | p-value |
| Lignée | 5310,0 | 4 | 5310,0 | 4 | 1327,5 | 9,5 | 0, 000175 |
| Lieu | 21 220,9 | 5 | 21 220,9 | 5 | 4244,2 | 30,5 | 0, 000000 |
| Année | 3798,5 | 1 | 3798,5 | 1 | 3798,5 | 27,3 | 0,000041 |
| Lignée x Lieu | 30 963,9 | 29 | 4433,0 | 20 | 221,7 | 1,6 | 0,153252 |
| Lignée x Année | 9400,3 | 9 | 291,8 | 4 | 73,0 | 0,5 | 1,00000 |
| Année x Lieu | 31 913,3 | 11 | 6893,9 | 5 | 1378,8 | 9,9 | 0, 000070 |
| Total | 44 732,4 | 59 | 2784,2 | 20 | 139,2 |
Légende:
Carrés: somme des carrés des écarts à la moyenne (SC) totaux
ddl (degré de liberté): correspond au nombre de termes utilisés dans le calcul de SC -1.
Intéraction: somme des carrés des écarts à la moyenne résiduel (SC résiduel)
ddl: degré de liberté résiduel
Variance: variance résiduelle normalisée c'est à dire Intéraction (SC résiduel) / ddl résiduel Ce critère donne une mesure de l'information moyenne contenue dans chaque cas du tableau.
F: valeur de la variable de Fisher: cette mesure permet d'évaluer la part d'information dans notre tableau de départ. Une petite explication s'impose.
L'information totale contenue dans les données initiales peut se décomposer en 3 termes: information 1D+ information 2D + information résiduelle 3D. Sachant que l'on a admis au départ que le tableau 3D de départ était inexploitable, alors par extrapolation on peut dire que l'information résiduelle 3D est négligeable. Ainsi, pour tout autre tableau de dimension inférieure, on pourra considérer qu'une information inférieure à cette information résiduelle 3D est elle aussi négligeable.
La variable F correspond à la comparaison entre l'information en cours d'analyse et l'information résiduelle négligeable, ici information 3D.
F = variance que l'on analyse/ variance résiduelle 3D. Sur la base de la valeur de F, on va pouvoir prendre la décision de garder ou non une information.
Si F est inférieur à 1, cela veut dire que la variance étudiée est négligeable, donc on ne conservera pas l'information concernée
Si F très supérieur à 1, cela veut dire que la variance étudiée est largement au dessus de ce qui est négligeable donc on conservera l'information concernée.
Si F proche de 1, on utilisera la loi de Fisher qui donne la probablité pour obtenir une telle valeur par hasard (p-value). Le choix de conserver ou non notre information se fera alors sur la base de la p-value. Plus cette probabilité est faible, moins notre résultat est lié au hasard et plus notre information est pertinente.
Nous allons voir dans la partie suivante comment utiliser le logiciel GeneANOVA dans ce contexte d'analyse de variance.

© Université
de TOURS - GÉNET
Document modifié le
30 septembre, 2008
![]()
![]()
![]()