Le traitement et la correction du bruit de fond est un question redondante en traitement de données surtout lorsque ces données sont obtenues par acquisition d'un signal comme c'est le cas pour les données du transcriptome (fluorochrome, radioactivité, ...).
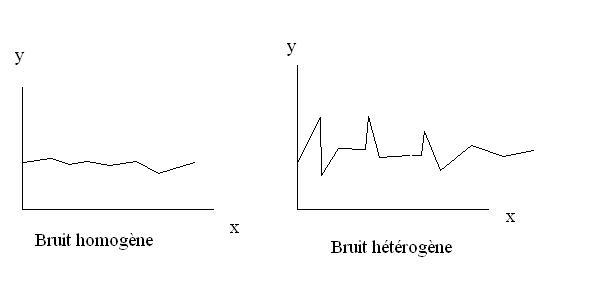
Deux situations peuvent se présenter et sont illustrées dans la figure ci-dessous:
- le bruit de fond est homogène à l'échelle de la largeur d'une tache. Dans ce cas, il suffit de retirer la moyenne du bruit à toutes les données et l'on dispose de données corrigées de bonne qualité.
- le bruit de fond est hétérogène. Dans ce cas, il n'est pas trivial de trouver comment retirer ce bruit. Pour faire simple, si l'on a pas de modèle de ce que l'on attend, on ne peut pas retirer le bruit.
Estimation de la qualité des transformations réalisées
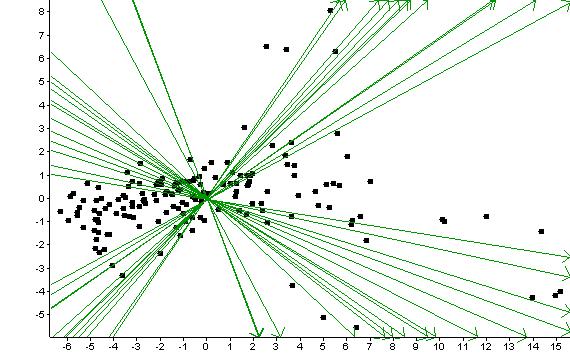
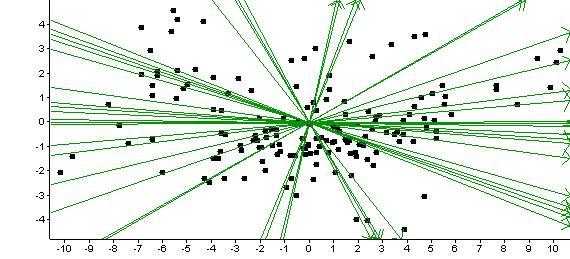
La question est de savoir si les diverses transformations que l'on peut effectuer sur un nuage de points constituent une amélioration ou non. Le critère numérique qui permet de quantifier cet aspect est la valeur de la première valeur propre avant et après transformation. Si cette valeur propre augmente après avoir traité les données, on peut conclure que l'on a amélioré la qualité de la représentation. A l'inverse, si cette valeur propre diminue, alors on a dégradé la qualité du nuage en effectuant le traitement des données. Enfin, si cette valeur propre reste stable, le traitement réalisé n'a servi à rien !!!
Exercice sur les données des plates-formes:
Deux jeux de données sont à votre disposition: le premier (Brut0) contient les données d'origine de l'expérience. Le second (JLRlog0), contient les données après correction du bruit de fond. Utilisez GeneAnova pour faire une ACP sur les deux séries de données et comparez les premières valeurs propres. Concluez quand à l'intérêt dans cet exemple de la correction qui a été faite pour diminuer le bruit de fond.
Pour voir les résultats sur Brut0: cliquez ici.
Pour voir les résultats sur JLRlog0: cliquez ici.
Conclusion: Effets du passage aux log après la correction du bruit de fond
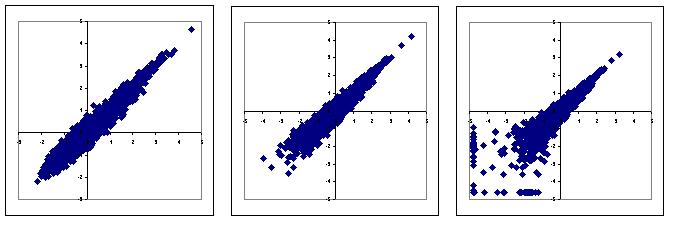
Les figures ci-dessous représentent l'expression des gènes dans deux conditions expérimentales. Chaque condition a été normalisée, c'est-à-dire que l'intensité mesurée par le photomultiplicateur a subi une transformation logarithmique puis une transformation linéaire de telle sorte que la moyenne du log des intensités soit égale à 0 et la variance à 1.
Gauche : données initiales x j (min = 160)
Milieu : données corrigées x j 160 + 0,01
Droite : introduction d'un seuil x j 230 + 1 si x j > 230 autrement 1

© Université
de TOURS - GÉNET
Document modifié le
21 avril, 2008
![]()
![]()
![]()
{kind=link}
{kind=link}