Analyse de variance: utilisation de GeneANOVA
1- Utilisation de geneANOVA sur les données de Mather
Le fichier de données sur lequel nous travaillons est orge.txt.
Les différentes étapes pour réaliser une analyse de variance (ANOVA) avec geneANOVA
- Création d'un design: c'est une nouveauté par rapport à l'ACP et cette étape est absoluement indispensable pour indiquer au programme comment structurer les sous tableaux. Les données initiales sont vues comme un flot linéaire de chiffres et pour que l'analyse de variance puisse se faire correctement, il faut fournir les informations nécessaires à la création de tous les sous tableaux de dimension inférieure.
Dans l'exemple des données sur l'orge, les différentes informations à fournir sont résumées dans le fichier orge.design. Pour plus de détails pour un premier contact avec le logiciel, la création de ce design sur l'orge est présentée dans le fichier creation_design_orge.htm.
- Les résultats sont présentés et discutés dans le fichier resultat_anova_orge.htm.
2-Utilisation de GeneANOVA sur les données du transcriptome:
Précedemment, nous avons présenté le choix des données sur l'orge (travail de Mather) par le fait que le tableau de données présentait la même structure logique que les données du transcriptome. Tout ce que nous venons de vous expliquer sur la méthode ANOVA va donc s'appliquer de ce fait au données du transcriptome. Concernant le choix du logiciel pour faire le travail, tous les calculs pourraient être fait dans Excel, mais nous avons à notre disposition GeneANOVA qui est totalement dédié à l'analyse du transcriptome, donc profitons en !!
Les données sur lesquelles nous allons travailler sont celles déjà utilisées pour la présentation de l'ACP (voir plan_experience.htm) sur le métabolisme de la méthionine chez B. Subtilis.
Les différentes étapes pour faire une analyse de variance sur des données du transcriptome:
- Pour les mêmes raisons que pour l'ACP, il faut préalablement traiter l'information par une transformation linéaire qui visent à centrer réduire les données.
- Création d'un design: vous le trouverez décrit en cliquant ici.
- Choix entre ANOVA globale et locale:
- Les résultats obtenus sont présentés et discutés dans le fichier: resultat_anova_subtilis.htm.
![]()
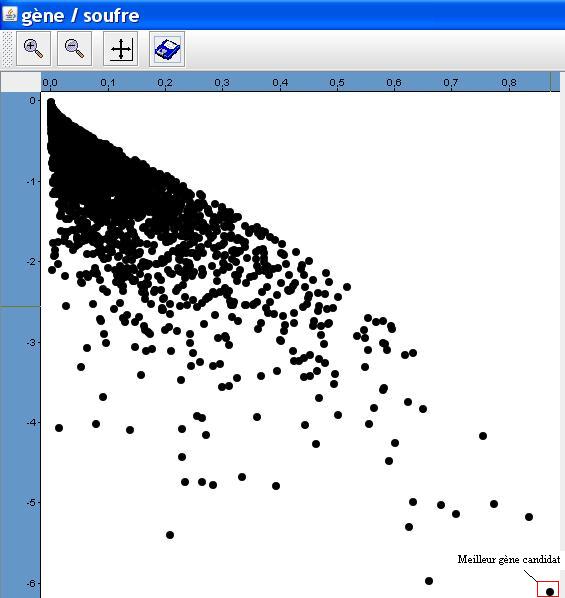
Représentation graphique ANOVA locale
Le graphique fourni par geneANOVA a pour abcisse la variance normalisée (soufre/totale) et pour ordonnée log(p-value). Les points (gènes) les plus intéressants seront ceux qui ont à la fois une p-value significative (p-value tend vers 0 donc log(p-value) tend vers -infini) et une variance normalisée élevée (part importante du soufre dans la variance totale).
Exemple de graphique gène soufre où le meilleur gène candidat pour l'analyse de l'effet soufre est encadré en rouge.
Analyse des données par voisinage:
Deux angles d'approche peuvent être utilisés:
- on repère un gène d'intérêt et on regarde sur le graphique quels sont les autres gènes dans son voisinage proche. Peut-on alors trouver un lien biologique (présent dans un même opéron, actif dans une même chaîne métabolique, situé dans la même région chromosomique, ...) entre le gène d'intérêt et ses plus proches voisins ?
- on prend un groupe de gènes ayant un lien biologique (cf ci-dessus) et on regarde sur le graphique comment sont situés ces gènes. Sont-ils groupés dans le même secteur ou au contraire totalement dispersés ?
Ce second angle d'approche est celui privilégié dans le travail sur le métabolisme de l'arginine proposé dans l'article, où les différents gènes de la chaîne du métabolisme de l'arginine sont étudiés. Dans le même esprit, les gènes de 3 opérons de B.subtilis ont été étudiés dans l'article (figure 8).
![]()
Le cas des plans d'expérience incomplets ou comment traîter les répétitions dans le cas de mesures non apparaillées
Cette partie vise à mettre en garde les personnes qui souhaitent faire de l'analyse de variance sans avoir préalablement vérifié que leur plan d'expérience est complet. Dans la mesure ou la méthode ANOVA nécessite la création d'un design, cela sous entend obligatoirement d'avoir des chiffres à mettre dans toutes les cases de tous les sous tableaux. L'exemple qui illustre cette difficulté porte sur l'expérience des plateformes présentées dans la partie plan_experience. Dans cette expérience, si l'on veut analyser l'effet du facteur dêpot, cela ne va pas être possible. En effet, les différentes membranes étant faites sur des sites différents, il n'y a aucune cohérence permettant de retrouver un biais systématique (il n'y a pas de raison à priori pour que le dépot 1 de la condition AX se comporte de façon identique au dépot 1 dans la condition BX).
Comment traiter l'information dans ce genre de situation ?
- Possibilité 1: on peut être tenté d'additionner 1 et 2 et traiter uniquement les autres facteurs en repartant d'un tableau réduit. Ce serait une erreur car en effectuant cela on perd des ddl donc de l'information.
| A | B | C | D | E | F | G | |
| x | |||||||
| y |
- Possibilité 2: on peut analyser malgré tout le tableau complet de départ mais en n' identifiant pas le facteur dêpot lors de l'entrée des paramètres dans l'analyse de variance. Dans ce cas, l'information liée à ce facteur passe dans le bruit.
Les meilleurs résultats pour traiter cette situation des mesures non appareillées consiste donc à faire une analyse du tableau complêt sans rentrer le facteur litigieux dans la liste des facteurs.

© Université
de TOURS - GÉNET
Document modifié le
25 mars, 2010
![]()
![]()