|
Analyse
bioinformatique des séquences
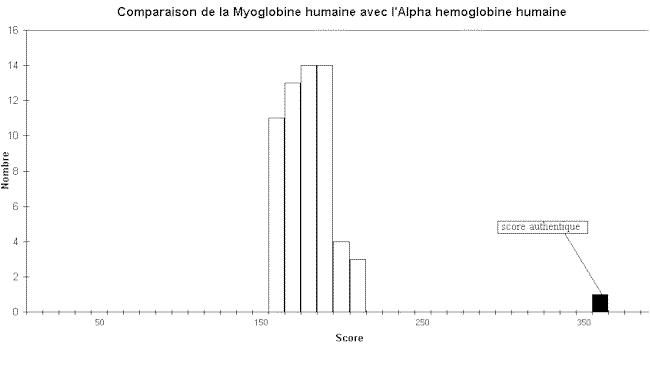
Une application directe de cette approche consiste à calculer un deuxième score qui rend compte de l'éloignement par rapport à la distribution aléatoire. Un tel score, que l'on nomme score Z, est déterminé de la manière suivante (Dayhoff, 1978 ; Doolitlle, 1981) : Z = (s - m) / e où s est le score authentique, m est la moyenne des scores aléatoires et e l'écart type des scores aléatoires. Le calcul d'un tel score Z suppose que la distribution des scores aléatoires suit une loi normale centrée réduite. Or on sait que cela est rarement exact (Waterman, 1989 ; Karlin et Altschul, 1990). On observe plutôt une loi de distribution de valeurs extrêmes avec la présence d'une queue de distribution pour les scores les plus élevés (Altschul et al., 1994). De ce fait, pour avoir une bonne confiance dans la signification du score, il faut prendre une valeur de Z élevée. C'est pourquoi lorsque l'on exprime le score Z en nombre d'écart-types pour estimer la comparaison, on utilise généralement plus de 2 écart-types (2e) qui est la valeur couramment admise pour une loi normale. On considèrera donc ici qu'a partir de 3e, la comparaison peut être significative, mais peu probable, qu'à partir de 6e, elle est significative et qu'au delà de 10e, elle est certaine. Ces méthodes présentent donc certains inconvénients. Le plus important est que l'hypothèse de normalité de la distribution des scores aléatoires n'est pas souvent vérifiée, ce qui implique que l'estimation de la signification du score peut être approximative. De plus, les modèles utilisés pour simuler des séquences ne sont pas toujours les mieux adaptés car ils ne prennent généralement pas en compte la taille des mots ou des syllabes qui constituent des unités fondamentales dans l'organisation des séquences (pour plus d'informations voir les études sur la linguistique des séquences comme celle de Kalogeropoulos, 1993). La non considération de ces éléments introduisent donc un biais dans les simulations. Enfin ces méthodes peuvent être parfois coûteuses en temps de calcul car elles nécessitent au minimum 100 scores par séquence pour une distribution suffisante des scores aléatoires. 
Autres méthodes |
